Current Projects
Conversational Strategies and Status in Information-gathering during Natural Disaster
In this current project, we investigate how those geographically-vulnerable to the hazards of the 2017 hurricanes Harvey and Irma utilized various conversational strategies to garner attention and solicit replies from the official news and government accounts, as part of their information-gathering activities. We also investigate the role of social status and popularity in users’ ability to get replies from the official accounts.
Quantifying Attention-garnering Content on Social Media
In this project, we focus on the role of attention on social media platforms, where the loudest voices often tend to dominate the discourse. This is especially salient in high-tempo, high-stakes environment of disaster, where choices of information sources can have real consequences. We utilize information-theoretic approaches to develop a method for quantifying the attention-garnering aspects of social media content in a principled, scalable way.
Deep Learning for Opinion Mining
While Natural Language Processing (NLP) techniques like topic modeling and sentiment analysis have been popular in social media analytics, their descriptive power over conversational dynamics is rather limited. For example, two people might discuss the same topic with the same general sentiment, but approach it from very different perspectives. In this project, we utilize deep learning approaches to develop methods for classifying social media content based on opinion, rather than topic or sentiment.
Network Dynamics around Collective Identity in Political Crisis
This project engages with the questions around dynamics of national, regional, and more broadly collective identity. In one strand of research, we investigate how competing notions of national identity permeate the social media discussions and propagate through the network in response to the 2014 Ukrainian revolution. In a broader research agenda, we are interested in exploring the questions of collective identity on social media in the context of other political disruptions, including those in the U.S.
Past Projects
Information Diffusion and Sense-making in Hurricane Sandy
As part of my dissertation work, I have worked in collaboration with the National Center for Atmospheric Research on project CHIME, in which we investigated “protective decision-making” practices of Twitterers active during coastal hazards.
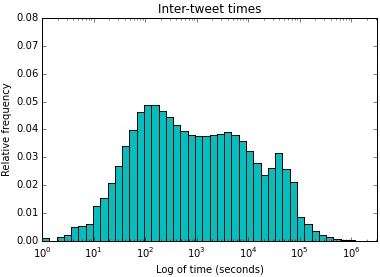
In one strand of research, I focused on Twitter information diffusion in the 2012 Hurricane Sandy. Specifically, I investigated how those geographically-vulnerable to the event propagated information online and whether they spread information differently from the general Twittersphere, including what and whose content they chose to propagate. I investigated whether the Twitter-based relationships are preexisting or if they are newly formed because of the disaster, and if so if they persist. The resulting CSCW paper shows that the people in the path of the disaster favor in their retweeting locally-created tweets and those with locally-actionable information. They also form denser networks of information propagation during disaster than before or after.
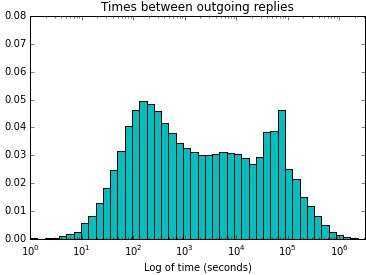
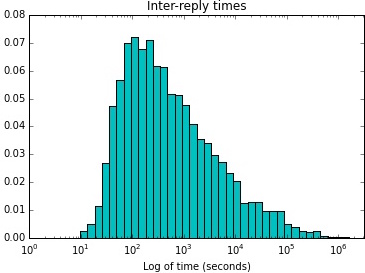
In another strand of research, I investigated the conversational activity that takes place through the @reply convention in disaster. I developed a method for constructing @reply conversations in Twitter at scale and applied it to the the high-tempo, high-stakes environment of 2012’s Hurricane Sandy. I investigated the temporality of conversations; the relationality of who speaks to whom; the number and kind of conversationalists; and how content affects temporal features. The resulting CHI paper shows that, during the height of the emergency, people expand conversations both in number and kind of conversational partners. This expansion contributes to longer, slower-paced conversations in the high-emergency period, suggesting reliance on online relationships during times of greatest uncertainty.
Work Practices and Cooperation in OpenStreetMap
As part of my dissertation work, I explored the work practices and interactions of volunteer mappers operating in the high-tempo, high-volume context of disasters. I built upon and expanded prior network analysis techniques to select high-value portions of the vast OSM data for further qualitative analysis. I then performed detailed content analysis of the identified activity and, where possible, conducted interviews with the participants. This research allowed the identification of seven distinct mapping practices that can be classified according to dimensions of time, space, and interpersonal interaction. After the salient work practices were identified, I used network motifs to further refine our methods, so they can more easily isolate the practices. The resulting CHI paper represents a baseline for future research about how OSM crisis mapping practices have evolved over time.

Analytics for OpenStreetMap History Data
In collaboration with my colleagues, we developed epic-osm: a software framework for OpenStreetMap full-history analysis. We have built a framework on Ruby and MongoDB with a static Jekyll and Javascript front-end which enables analysis of OSM history files.
Sports dynamics
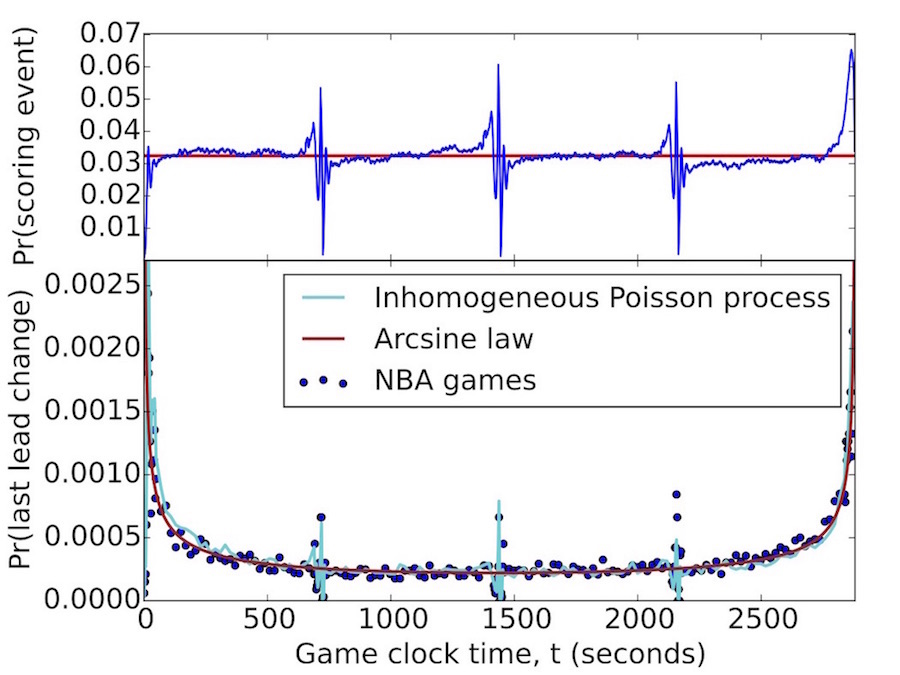
We investigated the time evolution of lead changes within individual games of competitive team sports. Exploiting ideas from the theory of random walks, the number of lead changes within a single game follows a Gaussian distribution. We show that the probability that the last lead change and the time of the largest lead size are governed by the same arcsine law, a bimodal distribution that diverges at the start and at the end of the game. We also determine the probability that a given lead is “safe” as a function of its size L and game time t. Our predictions generally agree with comprehensive data on more than 1.25 million scoring events in roughly 40 000 games across four professional or semiprofessional team sports, and are more accurate than popular heuristics currently used in sports analytics. This work has been published in Physical Review E and has been publicized in Slate and New Scientist.
Measuring Segregation based on Neighborhood Social Interactions
We used spectral methods to measure housing segregation at both the individual and community (neighborhood) level in 1880 Baltimore, while making use of the geographic and social structure in the population. Classic measures of segregation depend on the spatial resolution and they also do not account for any structure in the population, ignoring social relationships. Using Spectral Segmentation Index on the neighbor network allows us to overcome the level of granularity problem and make use of the inferred social relationships.